L’intelligence artificielle au service de la réduction des risques de catastrophe: possibilités, défis et perspectives
- Author(s):
- Monique Kuglitsch, Arif Albayrak, Raúl Aquino, Allison Craddock, Jaselle Edward-Gill, Rinku Kanwar, Anirudh Koul, Jackie Ma, Alejandro Marti, Mythili Menon, Ivanka Pelivan, Andrea Toreti, Rudy Venguswamy, Tom Ward, Elena Xoplaki, A. Rea et J. Luterbacher

L’intelligence artificielle (IA) et, en particulier, l’apprentissage par la machine (AM), jouent un rôle de plus en plus important dans la réduction des risques de catastrophe – de la prévision des phénomènes extrêmes à l’élaboration de cartes de dangers en passant par la détection de phénomènes en temps réel, l’aide à l’appréciation des situations, l’aide à la décision, etc. Cela soulève plusieurs questions: quelles sont les possibilités offertes par l’IA? Quelles difficultés soulève-t-elle? Comment remédier à ces difficultés et profiter de ces possibilités? et Comment utiliser l’IA pour faire parvenir des informations importantes aux décideurs, aux parties prenantes et au public et réduire ainsi les risques de catastrophe? Afin de réaliser le potentiel de réduction des catastrophes de l’IA et élaborer une stratégie pour l’IA appliquée à la prévention des catastrophes, nous devons répondre à ces questions et nouer des partenariats qui permettent de développer l’utilisation de l’IA dans la réduction des risques de catastrophe.
L’IA et son application à la réduction des risques de catastrophe
|
L’IA désigne des technologies qui imitent, voire dépassent, l’intelligence humaine dans l’exécution de certaines tâches. L’AM, qui est une composante de l’IA et recouvre l’apprentissage supervisé (par exemple, forêts aléatoires ou arbres de décision), l’apprentissage non supervisé (par exemple, K-moyens) et l’apprentissage par renforcement (par exemple, processus de décision de Markov), peut être décrit, en termes simplifiés, comme un processus qui entraîne un algorithme à apprendre à partir de ses données pour établir des classifications ou des prévisions. Les méthodes d’IA offrent de nouvelles possibilités d’application, par exemple au prétraitement des données d’observation et au post-traitement des résultats des modèles de prévision. Leur potentiel méthodologique est encore renforcé par les nouvelles technologies des processeurs, qui se prêtent à un traitement parallèle haute capacité des données.
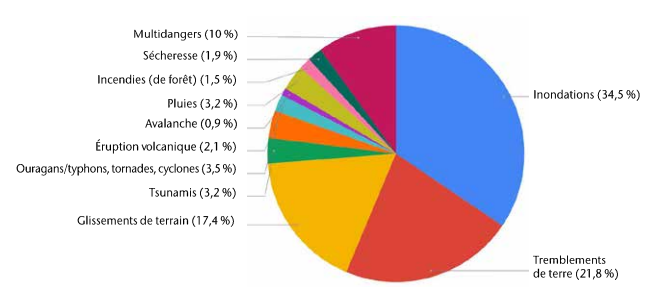
En général, les performances de l’AM pour une tâche donnée sont subordonnées à la disponibilité de données de qualité et au choix d’une architecture de modèle adéquate. Grâce à la télédétection (par exemple, à partir de satellites et de drones), aux réseaux d’instruments (par exemple à partir de stations météorologiques, hydrométéorologiques et sismiques) et à la production participative, notre corpus de données d’observation sur la Terre s’est considérablement étoffé. En outre, les architectures des modèles sont constamment affinées. Il faut donc s’attendre à ce que l’AM joue un rôle de plus en plus important dans les applications de réduction des risques de catastrophe (Sun et al., 2020). Par exemple, une revue des études récemment publiées (2018-2021) montre que l’AM est utilisé pour améliorer les systèmes d’alerte précoce et faciliter la production de cartes de dangers et de susceptibilité via la détection et la prévision par l’AM de divers types de dangers naturels (voir la figure 1; NB: cette revue n’inclut pas les recherches qui se concentrent strictement sur l’élaboration de méthodes, sans examiner les applications futures à la réduction des risques de catastrophe).
Cette étude préliminaire montre clairement que des méthodes d’IA sont actuellement appliquées pour nous aider à mieux gérer les conséquences de nombreux types de dangers naturels et de catastrophes. Dans les paragraphes qui suivent, nous présentons quatre exemples spécifiques dans lesquels l’IA est utilisée à l’appui de la réduction des risques de catastrophe.
En Géorgie, le Programme des Nations Unies pour le développement (PNUD) est en train d’établir un système national d’alerte précoce multidangers (MHEWS) qui vise à protéger les communautés, les moyens de subsistance et les infrastructures face aux risques naturels d’origine météorologique et climatique. Pour fonctionner, ce système a besoin de prévisions précises et de cartes des dangers liés aux systèmes de forte convection (c’est-à-dire les tempêtes de grêle et de vent). Cependant, la mise au point de ces produits est rendue difficile par le manque de réseaux d’observation in situ dans le pays. Aussi les experts ont-ils décidé d’utiliser l’IA pour créer un outil qui prédit la probabilité d’observer un phénomène convectif pour un jour déterminé à un endroit déterminé dans certaines conditions météorologiques et climatiques. Le modèle d’AM est capable de prévoir les situations de forte activité convective – plus précisément, il détecte les jours qui présentent un potentiel élevé de forte activité convective entraînant des tempêtes de grêle ou de vent – en combinant les observations in situ disponibles avec les données de la base de données sur soixante-dix années de tempêtes de l’Administration américaine pour les océans et l’atmosphère (NOAA) et le jeu de données de réanalyse de l’atmosphère de cinquième génération (ERA5) du Centre européen pour les prévisions météorologiques à moyen terme (CEPMMT). L’outil extrapole les données historiques des régions pour lesquelles on dispose de données abondantes à d’autres régions du monde pauvres en données en utilisant la technique de l’apprentissage par transfert. En dernier lieu, une réduction d’échelle est effectuée pour simuler et analyser ces phénomènes avec le modèle de prévision numérique du temps Weather Research and Forecasting (WRF) (Skamarock et al., 2019) et les données ERA5. Cette méthode s’est révélée très prometteuse pour la prévision des fortes tempêtes convectives et la production de cartes des dangers en Géorgie, une région qui pose des problèmes particuliers pour la prévision des tempêtes de grêle et de vent en raison de sa topographie complexe.
 Figure 2. Photographie d’une crue éclair à Manzanillo, au Mexique. (Source: Ricardo Ursúa.) Figure 2. Photographie d’une crue éclair à Manzanillo, au Mexique. (Source: Ricardo Ursúa.) |
Le deuxième exemple, qui a trait aux crues éclair, montre également comment l’IA permet de s’accommoder de jeux de données limités. Les crues éclair sont particulièrement dangereuses, car en général, il n’y a pratiquement pas de signes avant-coureurs de l’imminence d’une catastrophe. Pour détecter ces phénomènes rapidement, il est important de disposer d’un réseau dense de capteurs pour surveiller et déceler les changements de débit ou de hauteur dans le bassin versant. Dans le bassin hydrographique de Colima au Mexique, dont l’altitude s’échelonne entre 100 et 4 300 mètres, les stations hydrologiques sont complétées par un réseau multicapteurs composé de capteurs RiverCore (pour la hauteur et l’humidité du sol) et de stations météorologiques (Mendoza-Cano et al., 2021; Ibarreche et al., 2020; Moreno et al., 2019). Les données issues de ces instruments sont utilisées pour entraîner des modèles d’AM à la détection des crues éclair (voir la figure 2). On compare ensuite les résultats des modèles d’AM aux modèles hydrologiques/hydrauliques, puis l’on calcule des mesures de performance, telles que la précision globale, le score F1 et l’indice de Jaccard (IoU). Au vu du succès de cet exemple d’application à Colima, les mêmes méthodes sont en train d’être appliquées à la détection des crues éclair dans les tunnels urbains de la région métropolitaine de Guadalajara.
Le troisième exemple montre comment l’IA peut être exploitée en géodésie pour détecter les tsunamis et éviter les problèmes liés à la transmission de données sensibles au-delà des frontières nationales. L’application du traitement avancé en temps réel des données du Système mondial de navigation par satellite (GNSS) au positionnement et à l’imagerie ionosphérique apporte des améliorations très importantes à l’alerte précoce en cas de tsunami. Le GNSS est utilisé en sismologie pour étudier les déplacements du sol et surveiller les perturbations du contenu total d’électrons de l’ionosphère qui interviennent généralement dans le sillage d’un phénomène sismique. Il y a dix ans, lorsque les régions côtières du nord du Japon ont été frappées par le raz-de-marée du Tōhoku, il a fallu plusieurs jours pour saisir pleinement l’ampleur des dégâts. Combinées à l’IA et à l’AM, les observations de la Terre peuvent être mises à profit pour évaluer les menaces (Iglewicz et Hoaglin, 1993) et s’y préparer, pour évaluer les impacts au fur et à mesure qu’ils se produisent (dès 20 minutes après le tremblement de terre) (Carrano et Groves, 2009), et pour intervenir plus rapidement après coup, de manière à sauver des vies pendant les opérations de relèvement (Martire et al., 2021). Geodesy4Sendai, une activité communautaire du Groupe sur l’observation de la Terre (GEO) dirigée par l’Association internationale de géodésie (AIG) et l’Union géodésique et géophysique internationale (UGGI), prend part à une nouvelle initiative de collaboration sur les alertes précoces aux tsunamis avec l’Union internationale des télécommunications (UIT), l’OMM et le Groupe spécialisé sur l’intelligence artificielle au service de la gestion des catastrophes naturelles (FG-AI4NDM) du Programme des Nations Unies pour l’environnement (PNUE). Au sein du Groupe thématique sur l’IA au service de l’amélioration géodésique de la surveillance et de la détection des tsunamis, les experts ont commencé à se pencher sur les meilleures pratiques existantes en matière d’utilisation des données des GNSS (Astafyeva, 2019; Brissaud et Astafyeva, 2021). Plus précisément, les experts étudient la possibilité d’utiliser l’IA pour traiter les données GNSS dans les pays où l’exportation de données en temps réel est interdite par la loi, et d’établir des protocoles relatifs à l’élaboration et au partage de produits issus de l’IA et de méthodes connexes qui soient autorisés à l’exportation. Le groupe étudie également les possibilités offertes par les technologies de communication novatrices pour transmettre des données GNSS en temps réel à des pays ou des régions dont la capacité de bande passante est limitée, et où l’utilisation de l’IA pour le partage décentralisé de produits dérivés de données rendrait possible la transmission d’informations vitales sur des infrastructures de communication limitées. Ces recherches préparent le terrain pour une extension de l’utilisation de ces méthodes dans les pays en développement exposés à des menaces de tsunami grandissantes, en plus d’autres impacts du changement climatique tels que l’élévation du niveau de la mer (Meng et al., 2015).
Le quatrième exemple traite de la façon dont l’IA peut être utilisée pour assurer une communication efficace en cas de dangers ou catastrophes naturels. Plus précisément, il examine comment, suite à une catastrophe naturelle, l’IA peut aider les intervenants à évaluer la gravité des risques et à déterminer quand et où ils doivent agir en priorité. Les données structurées et non structurées, notamment les sources d’alerte sur les risques, les indicateurs de vulnérabilité, de susceptibilité et de résilience, ainsi que les sources d’information, sont intégrés à la plate-forme Operations Risk Insights (ORI), qui applique le traitement automatique du langage naturel et l’apprentissage par la machine pour visualiser et communiquer les risques multidangers en temps réel et aider à la prise de décision1 . Dans le cadre du programme Call for Code d’IBM, qui a été organisé à l’automne 2018 entre les ouragans Florence et Michael, IBM a mis ORI à la disposition d’organismes à but non lucratif qualifiés en matière de catastrophes naturelles. Depuis lors, IBM et plusieurs organisations non gouvernementales (ONG) se sont associés pour concevoir une plate-forme améliorée et personnalisée à l’usage des responsables de l’intervention en cas de catastrophe. Par exemple, ORI fournit à Day One Relief, Good360 et Save the Children des alertes personnalisées sur les ouragans et les tempêtes, ainsi que des ensembles de données en couches permettant de générer des cartes superposables qui donnent un meilleur aperçu de la situation2.
|
Difficultés relatives à l’application de l’IA à la réduction des risques de catastrophe
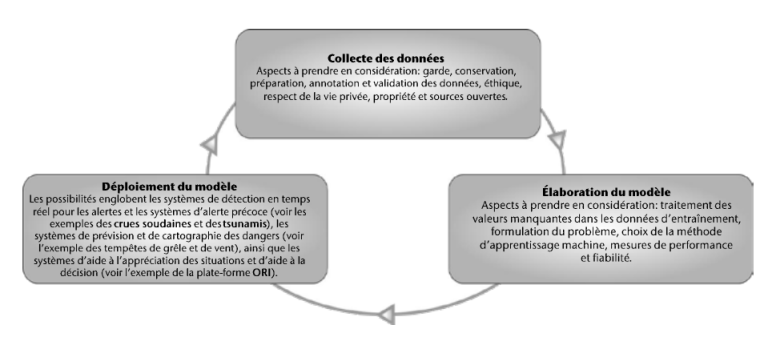
L’application de l’IA à la réduction des risques de catastrophe soulève un certain nombre de difficultés, qui peuvent survenir à n’importe quel stade du cycle de vie (voir la figure 3) – au niveau des données, de l’élaboration du modèle ou de la mise en œuvre opérationnelle.
Lors de la collecte et du traitement des données, il est important de prendre en compte: a) les biais dans les ensembles de données d’entraînement/de test, b) les nouvelles technologies de l’AI distribuée dans le domaine des données, et c) les questions éthiques. En ce qui concerne les biais dans les ensembles de données d’entraînement/de test, il faut veiller à ce que les données soient correctement échantillonnées et à ce que chaque configuration soit suffisamment représentée pour le problème considéré. Considérons, par exemple, le défi que représente la construction d’un ensemble de données représentatif contenant des exemples de phénomènes extrêmes (qui sont, par nature, rares). De même, il faut imaginer les coûts qu’entraînerait la fourniture de données inadéquates, en termes par exemple de prédictions erronées ou de résultats biaisés.
 Figure 4. L’élaboration de modèles d’IA capables de détecter des phénomènes tels que les tsunamis peut se heurter aux restrictions imposées à l’exportation des données. Cette image illustre l’impact du raz-de-marée de Tohoku en 2011. (Source: ArtwayPics, iStock: 510576834.) Figure 4. L’élaboration de modèles d’IA capables de détecter des phénomènes tels que les tsunamis peut se heurter aux restrictions imposées à l’exportation des données. Cette image illustre l’impact du raz-de-marée de Tohoku en 2011. (Source: ArtwayPics, iStock: 510576834.) |
Une fois que nous nous sommes assurés que l’ensemble de données considéré n’est pas biaisé, nous devons également décider comment intégrer les nouvelles technologies de l’IA distribuée dans le domaine des données. Les modifications stratégiques apportées à la construction des instruments spatiaux, comme les réseaux de petits satellites multiples3 et l’introduction de l’Edge Computing (Nikos et al., 2018), ont généré des pétaoctets de données. L’IA reposant sur la transmission de données et le calcul d’algorithmes d’apprentissage par la machine complexes, le traitement et la gestion centralisés des données peuvent poser des difficultés. D’une part, les applications de l’IA à la gestion des catastrophes en temps réel nécessitent des partenariats solides et un partage des données entre les pays (rappelons-nous l’exemple de l’application aux tsunamis; voir la figure 4). D’autre part, les algorithmes d’AM sont souvent exploités de manière centralisée, ce qui nécessite de fusionner les données d’entraînement dans des serveurs de données. Les approches centralisées peuvent également induire d’autres problèmes, tels que des risques pour la confidentialité des données personnelles et des données nationales. En outre, le traitement et la gestion centralisés des données peuvent limiter la transparence, suscitant la méfiance des utilisateurs finals ainsi que des difficultés pour se conformer aux réglementations (par exemple, le règlement général sur la protection des données (RGPD)).
Autre défi lié aux données, l’aspect éthique. Cet aspect concerne la manière dont il convient de mettre en œuvre les outils fondés sur l’IA, du développement au déploiement, en veillant, par exemple, à ce que les biais socio-économiques des données sousjacentes ne soient pas répercutés dans les modèles élaborés par le système. Il faut porter haut ces principes pour être en mesure d’atténuer, sinon d’éliminer, les inconvénients potentiels associés à l’IA, tels qu’une sous-représentation due à des biais (d’ordre technique ou humain), et s’assurer que les avantages de l’IA profitent à tous, notamment aux personnes rendues plus vulnérables par l’impact des dangers naturels4.
Une fois que l’ensemble de données a été conservé, il faut s’intéresser aux difficultés survenant au stade de l’élaboration du modèle. Nous allons ici nous concentrer sur les exigences liées au calcul et sur la transparence. Les modèles d’IA s’appuient généralement sur des structures complexes, de sorte que le processus d’entraînement peut exiger de très lourds calculs. Par exemple, le modèle VGG16 (Simonyan et Zisserman, 2015), utilisé pour la classification des images, compte environ 138 millions de paramètres entraînables. L’entraînement de modèles de cette taille nécessite des capacités de calcul élevées et coûteuses, qui ne sont pas accessibles à tous.
Une fois qu’un modèle d’IA a été mis au point, il est important que ses résultats soient compréhensibles et acceptables par les humains. Cela n’est pas toujours aisé, car il n’existe pas d’interface hommemachine générale clé en main qui explique comment et pourquoi certaines décisions sont prises par le modèle d’IA.
Par conséquent, de nombreux chercheurs travaillent à la mise au point de solutions d’IA dignes de confiance. Dans le cadre de la modélisation et de l’évaluation des modèles, par exemple, il est important de disposer d’une formulation précise du problème et de connaître les exigences et attentes de la solution d’IA. Ce n’est qu’à cette condition qu’un modèle et une stratégie d’apprentissage appropriés pourront être élaborés pour résoudre le problème. En outre, avoir une compréhension fine du dispositif facilite le choix et le développement des critères d’évaluation correspondants.
Pour qu’un modèle d’IA puisse être jugé prêt à l’exploitation, il faut tenir compte des difficultés recensées ci-avant – liées aux données et l’élaboration du modèle – ainsi que celles liées aux notifications adressées aux utilisateurs. Ces difficultés sont traitées au moyen de technologies de communication fondées sur l’IA. Pour améliorer et faciliter l’interprétation des résultats des modèles d’IA, ces résultats doivent être traduits et représentés visuellement d’une façon conforme aux besoins de l’utilisateur final. Il est donc essentiel que les parties prenantes – des communautés locales aux gestionnaires des systèmes d’urgence – et les responsables des interventions en cas de catastrophe au sein des ONG soient associés à la conception et à l’évaluation des systèmes d’alerte et d’avertissement précoce, des prévisions, des cartes des dangers, des systèmes d’aide à la décision, des tableaux de bord, des chatbots et autres outils de communication améliorés par l’IA. Des remontées d’information et des évaluations des résultats des modèles d’IA effectuées en temps utile par les personnes qui interviennent en cas de catastrophe sont essentielles pour améliorer la qualité et la précision des résultats. De même, faire la transparence sur les sources de données ingérées, la fréquence de rafraîchissement des données et les algorithmes utilisés par les outils de communication est capital pour établir un climat de confiance et affiner les recommandations issues de l’apprentissage par la machine. Comme pour les approches de modélisation traditionnelles, communiquer des informations compréhensibles sur les niveaux de confiance, les incertitudes et les limites d’un système assisté par l’IA est essentiel pour assurer une prise de décision en connaissance de cause. Au bout du compte, donner confiance dans des outils de communication fondés sur l’IA qui soient à la fois opportuns et totalement transparents est le plus grand défi à relever. Cela passera par une collaboration efficace entre les spécialistes expérimentés qui interviennent en cas de catastrophe, les développeurs de solutions d’IA, les spécialistes des géosciences, les instances de réglementation, les organismes publics, les ONG, les entreprises de télécommunication et autres, à même de répondre aux besoins de toutes les parties prenantes. Chaque type de catastrophe est unique, et chaque région présente des facteurs de vulnérabilité et des niveaux de résilience qui lui sont propres.
Initiatives pour remédier aux difficultés relatives à l’application de l’IA à la réduction des risques de catastrophe
Diverses initiatives concertées se sont donné pour objectif de remédier aux nombreuses difficultés soulevées par l’application de l’IA à la réduction des risques de catastrophe et faciliter son utilisation. Elles portent sur l’amélioration de l’accès aux données, la fourniture de logiciels et de progiciels d’appui au développement de l’IA, l’amélioration de l’explicabilité des modèles, la mise au point de nouvelles applications pour les méthodes fondées sur l’IA (jumeaux numériques) et l’élaboration de normes.
Comme nous l’avons déjà indiqué, l’une des plus grandes difficultés rencontrées dans l’élaboration d’algorithmes d’IA appliqués à la prévention des catastrophes est de faire en sorte que les données soient correctement échantillonnées et que, pour un problème déterminé, chaque configuration soit suffisamment représentée. De ce point de vue, les jeux de données ouverts (ou jeux de données «d’étalonnage»)5,6,7 peuvent constituer une ressource précieuse. En mettant leurs données en libre accès, les équipes espèrent que d’autres chercheurs les utiliseront pour améliorer et compléter les solutions existantes. Pour cela, il faut que les données fournies soient bien documentées – notamment qu’elles soient accompagnées de métadonnées – et accessibles. Des mesures doivent être prises pour bloquer, supprimer ou modifier les données de manière à éviter la transmission fortuite de données personnelles identifiables. En outre, il est conseillé de fournir une documentation claire indiquant comment télécharger les données et commencer à les exploiter. De nombreuses équipes accompagnent les projets qu’elles mettent en libre accès avec une excellente documentation, mais ne constatent pas de hausse des utilisations du simple fait que leurs données manquent de visibilité. Pour résoudre ce problème, une solution consiste à insérer des liens vers les données ouvertes sur Google Datasets, Kaggle, Github ou d’autres plates-formes de découverte de données. Le Groupe sur l’observation de la Terre (GEO), l’Administration nationale de l’aéronautique et de l’espace (NASA), l’Agence spatiale européenne et d’autres organismes ont édité des lignes directrices et/ou établi des bases de données pour encourager le libre accès aux données8.
 Figure 5. Image annotée extraite de l’outil NASA Worldview Search de l’initiative SpaceML, qui montre l’ouragan Sam au-dessus de l’océan Atlantique le 29 septembre 2021. (Source: image prise par NOAA-20/VIIRS.) Des outils novateurs fondés sur l’IA sont capables d’automatiser l’identification des phénomènes atmosphériques et des catastrophes naturelles – comme les ouragans – à partir d’images satellites. Figure 5. Image annotée extraite de l’outil NASA Worldview Search de l’initiative SpaceML, qui montre l’ouragan Sam au-dessus de l’océan Atlantique le 29 septembre 2021. (Source: image prise par NOAA-20/VIIRS.) Des outils novateurs fondés sur l’IA sont capables d’automatiser l’identification des phénomènes atmosphériques et des catastrophes naturelles – comme les ouragans – à partir d’images satellites. |
Outre les données en source ouverte, les développeurs de solutions d’IA peuvent mettre à profit toute une panoplie d’outils qui facilitent les principaux aspects du déploiement de l’IA: collecte des données, élaboration du modèle, déploiement du modèle et réentraînement/surveillance du modèle. Pour chacun de ces aspects, les développeurs d’IA ont à leur disposition plusieurs outils privés et en libre accès. Par exemple, de nombreux scientifiques s’appuient sur des images en source ouverte, qui sont annotées à la main par une équipe de chercheurs. Cependant, les systèmes de fichiers partagés qui aident à la collecte des données et automatisent l’annotation (par exemple, les caractéristiques pertinentes dans les images satellitaires; voir la figure 5) peuvent amener des gains d’efficacité. Une fois les données annotées, le praticien de l’apprentissage par la machine ou de la science des données devrait utiliser les progiciels les plus courants (par exemple, Python Tensorflow, Keras et Pytorch). Nombre des cadres d’architecture et d’entraînement de modèles les plus connus sont à même de simplifier les tâches d’IA. Par exemple, Pytorch Lightning est un cadre qui se superpose à Pytorch et qui facilite la gestion des données dans les modèles individuels. Enfin, en ce qui concerne le déploiement et la surveillance des modèles, il existe des solutions qui peuvent être exécutées en interne (c’est-à-dire en dehors du cloud). Elles nécessitent de disposer d’un serveur de modèle dédié et d’avoir des garanties quant à la disponibilité et à la période de latence du modèle. En outre, avant d’opter pour ce type de solution, il peut être sage d’examiner l’utilisation envisagée, le coût des ressources, le nombre de personnes formées pour assurer la disponibilité du modèle et, enfin, la fréquence à laquelle, selon les prévisions, il faudra réentraîner le modèle. Des systèmes tels que AWS Lambda et Gateway, Sagemaker, la plate-forme Google AI et l’outil de déploiement de modèle Watson sont capables de gérer les serveurs pour les tâches propres à l’AM, mais nécessitent tout de même d’avoir à porter de main des ressources d’AM/de science des données pour garantir la précision, le réentraînement et la disponibilité du modèle.
Une fois qu’un modèle a été mis au point, reste à résoudre, dans le cas d’applications à fort enjeu, le problème de la «boîte noire». Comment pouvons-nous avoir confiance dans un modèle si nous ignorons comment il prend ses décisions? L’EXplainable AI (XAI) est un domaine de recherche en pleine effervescence, qui produit des outils pouvant être utilisés à différentes étapes du cycle de vie de l’IA. Par exemple, les modèles d’IA sont souvent entraînés sur un vaste ensemble de données, pour parvenir à un niveau d’exactitude très élevé. Cependant, les raisons pour lesquelles un modèle est plus ou moins performant qu’un autre sont souvent difficiles à cerner. À l’aide d’outils XAI tels que les gradients intégrés (Sundararajan et al., 2017) ou la propagation de la pertinence par couches (Bach et al., 2015), on peut analyser le modèle et l’importance des caractéristiques apprises dans les données d’entrée afin de déterminer quels éléments sont les plus pertinents pour une prédiction. En passant de ces méthodes XAI locales à des méthodes globales, on peut également mettre au jour les déséquilibres éventuels des données, et même faire en sorte que des algorithmes soient «désappris» (Anders et al., 2022).
Les possibilités révolutionnaires qu’offre l’IA pour les approches et services de réduction des risques de catastrophe encouragent le partage de données en source ouverte, la mise au point d’outils et le renforcement des recherches sur l’IA (par exemple, sur l’XAI). Par exemple, les jumeaux numériques de la Terre (c’est-à-dire les répliques numériques du système terrestre et de ses composants) devraient susciter des avancées majeures dans la conception d’écosystèmes numériques innovants (Nativi et al., 2021), fondées sur des fédérations orientées utilisateur/service de calcul haute performance GPU/CPU et des infrastructures logicielles dédiées (Bauer et al., 2021). Dans ce contexte, la Commission européenne a lancé l’initiative Destination Terre, dont certains des premiers jumeaux numériques et cas d’utilisation identifiés sont axés sur la réduction des risques de catastrophe. L’IA jouera un rôle essentiel dans la mise en œuvre et l’utilisation efficace des jumeaux numériques, permettant par exemple d’opérer un couplage et une représentation complets de la composante humaine en tant que partie intégrante du système Terre.
Autre activité importante qui peut faciliter l’application de l’IA à la réduction des risques de catastrophe, l’élaboration de normes – c’est-à-dire l’établissement de lignes directrices reconnues au niveau international. Les organisations internationales d’élaboration de normes, parmi lesquelles l’Organisation internationale de normalisation (ISO), la Commission électrotechnique internationale (CEI) et l’Union internationale des télécommunications (UIT), mènent actuellement d’importantes activités de normalisation dans le domaine de la gestion des catastrophes. D’autres organismes du système des Nations Unies, tels que l’OMM, le Programme des Nations Unies pour l'environnement (PNUE), le Bureau des Nations Unies pour la prévention des catastrophes (UNDRR) et le Programme alimentaire mondial (PAM), contribuent également à la production de règlements techniques, de cadres, de pratiques recommandées et de normes de facto dans ce domaine.
Ces normes axées sur les technologies ont généralement pour but d’améliorer l’efficacité opérationnelle des systèmes d’alerte précoce et de maintenir les services requis pour la reprise des activités après sinistre à partir des solutions technologies de l’information et de la communication (TIC) existantes, la normalisation de l’IA appliquée à la réduction des risques de catastrophe restant un domaine largement inexploré. Consciente de cette lacune, en décembre 2020, l’UIT, en collaboration avec l’OMM et le PNUE, a créé un Groupe spécialisé sur l’intelligence artificielle au service de la gestion des catastrophes naturelles. Actuellement, ce groupe a) examine comment l’IA pourrait être appliquée à la gestion des différents types de dangers naturels susceptibles de dégénérer en catastrophes, et b) élabore un ensemble de bonnes pratiques concernant l’utilisation de l’IA en soutien à la modélisation à diverses échelles spatio-temporelles et à la mise en œuvre d’une communication efficace pendant de tels épisodes. Le groupe spécialisé compte 10 groupes thématiques actifs, qui étudient les applications de l’IA aux phénomènes suivants: inondations, tsunamis, invasions d’insectes, glissements de terrain, avalanches de neige, incendies de forêt, maladies à transmission vectorielle, éruptions volcaniques, tempêtes de grêle et de vent, et risques multidangers; il examine en outre avec intérêt les propositions d’étude de thèmes supplémentaires. Pour mettre en évidence et comprendre les lacunes de l’application de l’IA à la prévention des catastrophes en matière de normalisation, le groupe est en train d’élaborer une feuille de route recensant les normes et les directives techniques existantes dans ce domaine, qui émanent de différentes OEN internationales, nationales et régionales. Cette feuille de route nous permettra d’identifier les domaines qui nécessiteront à l’avenir une attention particulière du point de vue de la normalisation. Enfin, le groupe spécialisé est en train de préparer un glossaire qui répertorie les termes et définitions utilisés dans ce domaine, pour favoriser une communication claire et dénuée d’ambiguïté et œuvrer à la cohérence des activités de normalisation en matière de réduction des risques de catastrophe.
Prochaines étapes
Dans le domaine de la réduction des risques de catastrophe, l’IA suscite un intérêt considérable en tant que moyen de renforcer les méthodes et stratégies existantes. Cet article a évoqué plusieurs cas d’utilisation montrant comment les modèles fondés sur l’IA peuvent améliorer la prévention des catastrophes. Cependant, il a aussi montré que l’IA ne va pas sans poser de problèmes. Heureusement, le potentiel prometteur de l’application de l’IA à la réduction des risques de catastrophe incite les chercheurs à trouver des solutions à ces défis et a donné lieu à de nouveaux partenariats, qui réunissent des experts spécialisés dans différents domaines scientifiques (informatique, géosciences), issus de divers organismes du système des Nations Unies, de divers secteurs (des universités aux ONG) et de toutes les régions du monde. De tels partenariats sont essentiels pour faire progresser l’utilisation de l’IA dans la réduction des risques de catastrophe. Nous pensons en particulier que des efforts supplémentaires seront nécessaires pour créer des outils didactiques permettant de renforcer les capacités, pour assurer une offre suffisante de ressources informatiques et d’autres matériels et pour réduire la fracture numérique. Ce n’est qu’ainsi que nous pourrons nous assurer que les progrès accomplis dans l’application de l’IA à la prévention des catastrophes ne laissent personne de côté.
Les membres de la communauté météorologique mondiale qui souhaitent en savoir plus sur cette application de l’IA peuvent se tourner vers les nombreux comités, conférences et rapports consacrés à cette question. Par exemple, le Comité des applications de l’intelligence artificielle aux sciences de l’environnement de l’American Meteorological Society et Climate Change AI offrent la possibilité de nouer des contacts avec d’autres experts du domaine. La séance consacrée à l’«intelligence artificielle pour les sciences de la Terre» lors de la récente conférence sur les systèmes de traitement de l’information neuronale (NeurIPS) et celle qui traitera de l’«intelligence artificielle pour la gestion des dangers et catastrophes naturels» lors de la prochaine Assemblée générale de l’Union européenne des géosciences sont deux exemples de conférences qui font découvrir des recherches et des cas d’utilisation très novateurs. Enfin, des rapports tels que «Responsible AI for Disaster Risk Management: Working Group Summary» peuvent donner des orientations supplémentaires.
Notes de bas de page
Auteurs
Par Monique Kuglitsch, Institut Fraunhofer Heinrich Hertz, Allemagne, Arif Albayrak, Centre de vol spatial Goddard de la NASA, États-Unis d’Amérique, Raúl Aquino, Université de Colima, Mexique, Allison Craddock, NASA Jet Propulsion Laboratory et California Institute of Technology, États-Unis d’Amérique; Jaselle Edward-Gill, Institut Fraunhofer Heinrich Hertz, Allemagne, Rinku Kanwar, IBM, États-Unis d’Amérique, Anirudh Koul, Pinterest, États-Unis d’Amérique, Jackie Ma, Institut Fraunhofer Heinrich Hertz, Allemagne, Alejandro Marti, Mitiga Solutions et Centre de calcul informatique de Barcelone, Espagne, Mythili Menon, Union internationale des télécommunications, Ivanka Pelivan, Institut Fraunhofer Heinrich Hertz, Allemagne, Andrea Toreti, Centre commun de recherche de la Commission européenne, Italie, Rudy Venguswamy, Pinterest, États-Unis d’Amérique, Tom Ward, IBM, États-Unis d’Amérique, Elena Xoplaki, Université Justus-Liebig de Gießen, Allemagne, et Anthony Rea et Jürg Luterbacher, Secrétariat de l’OMM
Références
Anders, C. J., L. Weber, D. Neumann, W. Samek, K.-R. Müller, S. Lapuschkin, 2022: Finding and removing Clever Hans: Using explanation methods to debug and improve deep models. Information Fusion, 77, 261-295.
Astafyeva, E., 2019: Ionospheric detection of natural hazards. Reviews of Geophysics, 57, 1265-1288. doi: 10.1029/2019RG000668
Bach, S., A. Binder, G. Montavon, F. Klauschen, K.-R. Muller, and W. Samek, 2015: On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation. PLoS ONE, 10(7):e0130140.
Bauer, P., P.D. Dueben, T. Hoefler, T. Quintino, T.C. Schulthess, and N.P. Wedi, 2021: The digital evolution of Earth-system science. Nature Computational Science 1, 104-113.
Brissaud, Q., and E. Astafyeva, 2021: Near-real-time detection of co-seismic ionospheric disturbances using machine learning, Geophysical Journal International, in review.
Carrano, C., and K. Groves, 2009: Ionospheric Data Processing and Analysis. Workshop on Satellite Navigation Science and Technology for Africa. The Abdus Salam ICTP, Trieste, Italy.
Ibarreche, J., R. Aquino, R.M. Edwards, V. Rangel, I. Pérez, M. Martínez, E. Castellanos, E. Álvarez, S. Jimenez, R. Rentería, A. Edwards, and O. Álvarez, 2020: Flash Flood Early Warning System in Colima, Mexico. Sensor Journal 20(18), 5231. doi: https:// doi.org/10.3390/s20185231
Iglewicz, B., and D. C. Hoaglin, 1993: Volume 16: How to Detect and Handle Outliers. The ASQC Basic References in Quality Control: Statistical Techniques.
Lu, Y., L. Luo, D. Huang, Y. Wang, and L. Chen, 2020: Knowledge Transfer in Vision Recognition. ACM Computing Surveys 53(2), 1-35. https://doi. org/10.1145/3379344
Martire, L., V. Constantinou, S. Krishnamoorthy, P. Vergados, A. Komjathy, X. Meng, Y. Bar-Sever, A. Craddock, and B. Wilson, 2021: Near Real-Time Tsunami Early Warning System Using GNSS Ionospheric Measurements. American Geophysical Union, New Orleans, Louisiana, USA.
Mendoza-Cano, O., R. Aquino-Santos, J. López-de la Cruz, R. M. Edwards, A. Khouakhi, I. Pattison, V. Rangel-Licea, E. Castellanos-Berjan, M. A. Martinez- Preciado, P. Rincón-Avalos, P. Lepper, A. Gutiérrez- Gómez, J. M. Uribe-Ramos, J. Ibarreche, and I. Perez, 2021: Experiments of an IoT-based wireless sensor network for flood monitoring in Colima, Mexico. Journal of Hydroinformatics 23(3), 385-401. doi: https://doi.org/10.2166/hydro.2021.126
Meng, X., A. Komjathy, O. P. Verkhoglyadova, Y.-M. Yang, Y. Deng, and A. J. Mannucci, 2015: A new physics-based modeling approach for tsunami-ionosphere coupling. Geophysical Research Letters 42, 4736–4744. doi:10.1002/2015GL064610
Moreno, C., R. Aquino, J. Ibarreche, I. Pérez, E. Castellanos, E. Álvarez, R. Rentería, L. Anguiano, A. Edwards, and P. Lepper, 2019: Rivercore: IoT device for river water level monitoring over cellular communications. Sensor Journal 19(1), 127. doi: https://doi.org/10.3390/s19010127
Nativi, S., P. Mazzetti, and M. Craglia, 2021: Digital ecosystems for developing digital twins of the Earth: the Destination Earth case. Remote Sensing 13, 2119.
Nikos, K., M. Avgeris, D. Dechouniotis, K. Papadakis-Vlachopapadopoulos, I. Roussaki, and S. Papavassiliou, 2018: Edge Computing in IoT Ecosystems for UAV-Enabled Early Fire Detection. IEEE International Conference on Smart Computing (SMARTCOMP) 106-114. doi: 10.1109/ SMARTCOMP.2018.00080
Simonyan, K. and A. Zisserman, 2015: Very Deep Convolutional Networks for Large-Scale Image Recognition. ICLR.
Skamarock, W.C., J.B. Klemp, J. Dudhia, D.O. Gill, L. Zhiquan, J. Berner, W. Wang, J.G. Powers, M.G. Duda, D.M. Barker, and X. Y. Huang, 2019: A Description of the Advanced Research WRF Model Version 4. NCAR Technical NoteNCAR/TN-475+STR. doi: http://library.ucar.edu/research/publish-technote.
Sun, W., P. Bocchini, and B.D. Davison, 2020: Applications of artificial intelligence for disaster management. Natural Hazards 103, 2631–2689. doi: https://doi.org/10.1007/s11069-020-04124-3
Sundararajan, M., A. Taly, and Q. Yan, 2017: Axiomatic attribution for deep networks. Proceedings of the 34th International Conference on Machine Learning, 3319–3328.
Troung, N., K. Sun, S. Wang, F. Guitton, and Y. Guo, 2021: Privacy preservation in federated learning: An insightful survey from the GDPR perspective. Computer & Security 110, 10/2021. doi: https://doi. org/10.1016/j.cose.2021.102402.