La inteligencia artificial aplicada a la reducción de riesgos de desastre: oportunidades, retos y perspectivas
- Author(s):
- Monique Kuglitsch, Arif Albayrak, Raúl Aquino, Allison Craddock, Jaselle Edward-Gill, Rinku Kanwar, Anirudh Koul, Jackie Ma, Alejandro Marti, Mythili Menon, Ivanka Pelivan, Andrea Toreti, Rudy Venguswamy, Tom Ward, Elena Xoplaki, A. Rea y J. Luterbacher

La inteligencia artificial (IA), en particular el aprendizaje automático, desempeña, cada vez más, un papel fundamental en la reducción de riesgos de desastre (RRD), desde la predicción de fenómenos extremos y el desarrollo de mapas de peligro hasta la detección de episodios en tiempo real y la aportación de conocimiento de la situación y apoyo a la toma de decisiones, entre otras funciones. Todo ello plantea múltiples cuestiones: ¿qué oportunidades presenta la IA?, ¿cuáles son los retos?, ¿cómo se pueden abordar los retos y beneficiarse de las oportunidades? Y, ¿cómo se puede usar la IA para suministrar información importante a las instancias decisorias, los grupos de interés y la población general para reducir los riesgos de desastre? Para darse cuenta del potencial de la IA en la RRD y articular una estrategia de inteligencia artificial para esta RRD, se deben abordar estas preguntas y forjar alianzas que impulsen la IA en la RRD.
La IA y su uso en la RRD
|
La IA se refiere a las tecnologías que emulan o, incluso, superan la inteligencia humana en la realización de ciertas tareas. El aprendizaje automático, que es un subgrupo de la IA que incluye el aprendizaje supervisado (p. ej., bosque aleatorio o árbol de decisión), no supervisado (p. ej., K-medias) o por refuerzo (p. ej., proceso de decisión de Markov), puede simplificarse como análisis de datos llevados a cabo por algoritmos que, en esencia, aprenden de los datos para hacer clasificaciones o predicciones. Los métodos de IA ofrecen nuevas oportunidades para aplicaciones como, por ejemplo, el procesamiento previo de los datos procedentes de la observación así como el posprocesamiento de las salidas de los modelos numéricos de predicción. El potencial metodológico se ve reforzado por las nuevas tecnologías de procesadores que facilitan el tratamiento de datos en paralelo y de alto rendimiento.
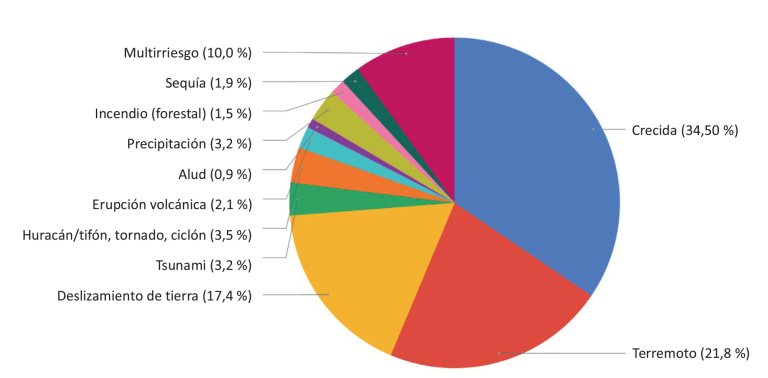
En general, el rendimiento del aprendizaje automático para abordar una tarea dada está basado en la disponibilidad de datos de calidad y en la selección apropiada de una arquitectura de modelos. A través de la teledetección (desde satélites, drones, etc.), redes instrumentales (meteorológica, hidrometeorológica, de estaciones sísmicas, etc.) y la colaboración abierta, la base de datos de observación de la Tierra ha crecido inmensamente. Asimismo, las arquitecturas de modelos están refinándose constantemente. Por consiguiente, se espera que el aprendizaje automático gane protagonismo en las aplicaciones de RRD (Sun y otros, 2020). Por ejemplo, un estudio preliminar de la documentación reciente (2018-2021) muestra que los enfoques de aprendizaje automático se están utilizando para mejorar los sistemas de alerta temprana y para ayudar a generar mapas de riesgos y vulnerabilidad a través de la detección y la predicción, impulsadas por este aprendizaje, de varios tipos de peligros naturales (véase la figura 1, hay que tener en cuenta que este estudio excluye la investigación que se centra únicamente en el desarrollo de métodos, pero que no tiene como objetivo la futura aplicación de RRD).
Este estudio preliminar pone claramente de manifiesto que los métodos de IA se están aplicando para ayudar a mejorar la gestión de los impactos de numerosos tipos de riesgos y desastres naturales. En los siguientes párrafos se presentan cuatro ejemplos específicos donde la IA se está implementando para dar apoyo a la RRD.
En Georgia, el Programa de las Naciones Unidas para el Desarrollo (PNUD) está poniendo en marcha un sistema de alerta temprana de peligros múltiples (MHEWS) de ámbito nacional para ayudar a reducir el grado de exposición de la población, los medios de subsistencia y las infraestructuras a los riesgos naturales meteorológicos y climáticos. Para su puesta en operación, este sistema requiere predicciones precisas y mapas de riesgos de fenómenos convectivos adversos (por ejemplo, granizo y vendavales). Sin embargo, elaborar tales productos es un reto, habida cuenta de la escasa cobertura de la red de observación in situ a lo largo del país. De esta forma, los expertos están empleando la IA para desarrollar una herramienta que pronostique la probabilidad de observar un fenómeno convectivo en un determinado día y en una localización dada, bajo unas condiciones meteorológicas y climáticas concretas. El modelo de aprendizaje automático está capacitado para predecir condiciones convectivas adversas, es decir, puede detectar qué días tienen un alto potencial de convección intensa que dé lugar a granizo o a vientos fuertes, combinando la disponibilidad de las observaciones in situ con datos de la base de datos de fenómenos tormentosos de 70 años de la Oficina Nacional de Administración Oceánica y Atmosférica (NOAA) y del conjunto de datos de reanálisis de 5ª generación (ERA5) del Centro Europeo de Previsiones Meteorológicas a Plazo Medio (ECMWF). Esta herramienta emplea datos históricos de regiones con abundantes observaciones para extrapolarlos a cualquier otra región del mundo cuya disponibilidad de observaciones es más limitada, utilizando el aprendizaje por transferencia. Finalmente, se usa la reducción de escala para simular y analizar estos episodios con el modelo WRF (Weather Research and Forecasting) de predicción numérica del tiempo (Skamarock y otros, 2019) y los datos de ERA5. Todo ello ha demostrado un gran potencial para predecir episodios de tiempo violento por convección y para elaborar mapas de riesgos en Georgia, una región especialmente singular para la predicción de granizo y fuertes vientos debido a su compleja orografía.
 Figura 2. Fotografía de una crecida repentina en Manzanillo (México) (Crédito: Ricardo Ursúa). Figura 2. Fotografía de una crecida repentina en Manzanillo (México) (Crédito: Ricardo Ursúa). |
El segundo ejemplo, que se refiere a las crecidas repentinas, aprovecha también la IA para sobrellevar la limitación de observaciones. Las crecidas repentinas son particularmente peligrosas porque, por lo general, hay pocos o ningún aviso previo para impedir el desastre. Cuando tienen lugar estos episodios, para detectarlos es importante disponer de una red de sensores lo suficientemente densa como para vigilar y detectar cambios en el caudal o en el nivel del agua entoda la cuenca. En la cuenca del río Colima, en México, cuya elevación varía de 100 a 4 300 metros (m), las estaciones hidrológicas se complementan con una red de multisensores compuesta por sensores RiverCore (para medir el nivel del agua y la humedad del suelo) y estaciones meteorológicas (Mendoza-Cano y otros, 2021; Ibarreche y otros, 2020; Moreno y otros, 2019). Los datos procedentes de la red se usan para preparar los modelos de aprendizaje automático, capaces de detectar crecidas repentinas (figura 2). Los resultados obtenidos de estos modelos se comparan con los modelos hidrológicos/hidráulicos y se determinan los criterios para evaluar su rendimiento, entre ellos: la exactitud general, el valor F y la relación intersección sobre unión. Debido al éxito del ejemplo del Colima, estos métodos se están extendiendo para detectar las inundaciones repentinas en los túneles urbanos del área metropolitana de Guadalajara.
El tercer ejemplo pone de manifiesto cómo la IA se puede usar en geodesia para detectar tsunamis y aminorar los problemas en relación con datos sensibles que trascienden más allá de las fronteras nacionales. La aplicación del procesamiento en tiempo real avanzado del Sistema mundial de navegación por satélite (GNSS) para el posicionamiento y la obtención de imágenes ionosféricas ofrece mejoras muy significativas para la alerta temprana de desastres por tsunami. El GNSS se usa en sismología para estudiar desplazamientos del suelo, así como para vigilar perturbaciones en el contenido total de electrones (TEC) de la ionosfera que comúnmente se dan en estos episodios. Hace diez años, cuando las costas del norte del Japón fueron golpeadas por el tsunami Tohoku, llevó varios días comprender la totalidad del desastre en su conjunto. Las observaciones de la Tierra, combinadas con la IA y el aprendizaje automático, se pueden usar para evaluar amenazas (Iglewicz y Hoaglin, 1993) y para prepararse con anticipación a fin de evaluar los impactos a medida que se desarrollan (tan solo 20 minutos después de la ocurrencia de un terremoto) (Carrano y Groves, 2009), y responder más rápidamente tras la catástrofe, para salvar vidas durante las operaciones de búsqueda y rescate (Martire y otros, 2021). Geodesy4Sendai, una acción comunitaria del Grupo de Observaciones de la Tierra (GEO) dirigida por la Asociación Internacional de Geodesia (AIG) y la Unión Internacional de Geodesia y Geofísica (UIGG), está participando en una nueva colaboración en materia de alerta temprana de tsunamis con la Unión Internacional de Telecomunicaciones (UIT), la Organización Meteorológica Mundial (OMM) y el Grupo focal sobre inteligencia artificial aplicada a la gestión de desastres naturales del Programa de las Naciones Unidas para el Medio Ambiente (PNUMA). En el seno del Grupo temático sobre IA para la mejora geodésica de la vigilancia y detección de tsunamis, los expertos han empezado a analizar las mejores prácticas relevantes en el uso de datos del GNSS (Astafyeva, 2019; Brissaud y Astafyeva, 2021). En particular, los expertos están explorando la fiabilidad del uso de la IA para procesar datos del GNSS en países donde la extracción de datos en tiempo real está prohibida por ley, y para crear protocolos de desarrollo e intercambio de productos con permiso de exportación obtenidos por la IA y sus métodos conexos. El grupo también está considerando el uso de tecnologías de comunicación innovadoras para transmitir en tiempo real datos del GNSS a países o regiones con capacidad limitada de ancho de banda, donde el uso de la IA para compartir productos descentralizados y derivados de los datos podría facilitar la transmisión de información para salvar vidas a través de una infraestructura de comunicaciones limitada. Tal esfuerzo sienta las bases para expandir el uso de esos métodos en países en vías de desarrollo que sufren el incremento de amenazas por tsunamis, así como los impactos del cambio climático, como el aumento del nivel del mar (Meng y otros, 2015).
El cuarto ejemplo explora cómo la IA puede usarse para ofrecer una comunicación eficaz en el caso de amenazas y desastres naturales; en concreto, cómo puede ayudar a los responsables a evaluar la gravedad del riesgo y priorizar cuándo y dónde responder. En la plataforma de información del riesgo de las operaciones, que aplica el procesamiento del lenguaje natural y el aprendizaje automático para visualizar y comunicar riesgos múltiples en tiempo real y asesorar en la toma de decisiones1, se introducen datos estructurados y no estructurados, como fuentes de alerta de riesgos, indicadores de vulnerabilidad, susceptibilidad y resiliencia, y nuevas fuentes. Como parte del programa de IBM Call for Code, que se llevó a cabo durante los huracanes Florence y Michael (otoño de 2018), se puso una plataforma de información del riesgo de las operaciones a disposición de las organizaciones sin ánimo de lucro competentes en desastres naturales. Desde entonces, IBM y numerosas organizaciones no gubernamentales (ONG) se han asociado para mejorar y personalizar una plataforma orientada a los responsables de la respuesta frente a desastres que, por ejemplo, suministra alertas personalizadas de huracanes y temporales, así como conjuntos de datos por capas para generar mapas superpuestos que ayudan a mejorar la conciencia situacional a las organizaciones Day One Relief, Good360 y Save the Children2.
|
Retos para el uso de la IA en la RRD
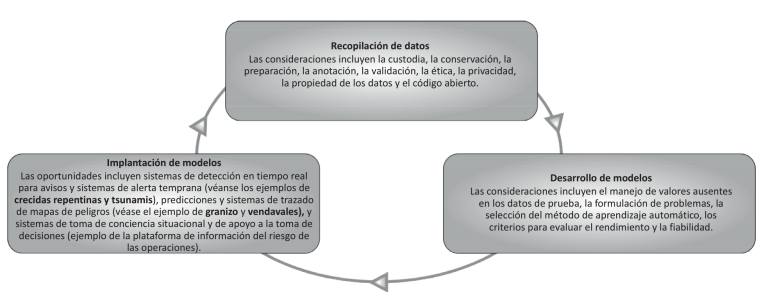
Cuando se aplica la IA a la RRD, pueden surgir problemas en cualquier fase del ciclo de vida (figura 3): en los datos, en el desarrollo del modelo o en la fase de implementación operativa.
Durante la recopilación y el tratamiento de datos, es importante considerar: a) los sesgos en el ajuste y la prueba de las bases de datos; b) las nuevas tecnologías de IA distribuida dentro del dominio de datos y c) las cuestiones éticas. En términos de sesgos en el ajuste y la prueba de bases de datos, es importante asegurarse de que los datos están correctamente muestreados y de que todos los patrones de los problemas en cuestión están suficientemente representados. Considérese, por ejemplo, el reto de construir un conjunto de datos representativo que contenga ejemplos de eventos extremos (que son, por naturaleza, excepcionales). También, imagínense los posibles costes del fallo en el suministro de los datos, por ejemplo, por predicciones erróneas o salidas sesgadas del modelo.
 Figura 4. La creación de modelos basados en la IA que pueden detectar ciertos fenómenos, como los tsunamis, puede verse dificultada por las limitaciones en la exportación de datos. Esta imagen muestra las consecuencias del tsunami de Tohoku de 2011 (Crédito: ArtwayPics, iStock: 510576834). Figura 4. La creación de modelos basados en la IA que pueden detectar ciertos fenómenos, como los tsunamis, puede verse dificultada por las limitaciones en la exportación de datos. Esta imagen muestra las consecuencias del tsunami de Tohoku de 2011 (Crédito: ArtwayPics, iStock: 510576834). |
Una vez que hay seguridad de que los conjuntos de datos no están sesgados, se necesita también decidir cómo integrar las nuevas tecnologías de IA distribuida dentro del dominio de datos. Las modificaciones estratégicas en la construcción de instrumentos espaciales como una multitud de pequeños satélites3 y la introducción de tecnologías informáticas vanguardistas (Nikos y otros, 2018) se han traducido en petabytes de datos. Dado que la IA se basa en la transmisión de datos y el cálculo de complejos algoritmos de aprendizaje automático, el procesamiento y la gestión de datos centralizados pueden plantear dificultades. En primer lugar, las aplicaciones de desastres en tiempo real requieren fuertes alianzas y el intercambio de datos entre países (recuérdese el ejemplo del tsunami; figura 4). Por otro lado, los algoritmos de aprendizaje automático frecuentemente se operan de modo centralizado, requiriendo que los datos de prueba se fusionen en servidores de datos. Un enfoque centralizado también puede presentar problemas adicionales, como riesgos de privacidad para datos personales y específicos del país. Además, el procesamiento y la gestión de datos centralizados pueden limitar la transparencia, lo que podría provocar una falta de confianza por parte de los usuarios finales, así como dificultades para cumplir la normativa (por ejemplo, el Reglamento general de protección de datos).
Otro problema asociado a los datos se vincula con las consideraciones éticas, que se centran en cómo deberían implementarse las herramientas de la IA desde el desarrollo hasta su implantación, asegurando, por ejemplo, que los sesgos socioeconómicos de los datos subyacentes no se propagan a través de los modelos desarrollados por el sistema. Estos principios se defienden para que los daños potenciales asociados a la IA, como la infrarrepresentación debido al sesgo (ya sea técnico o humano), puedan mitigarse, si no eliminarse, y para que todos puedan obtener los beneficios de la IA, especialmente los más vulnerables a los impactos de las amenazas naturales4.
Una vez que se ha conservado un conjunto de datos, también hay que tener en cuenta los retos durante la fase de desarrollo del modelo. En este caso, hay que centrarse en las exigencias computacionales y la transparencia. Los modelos de IA tienden a basarse en estructuras complejas y, por consiguiente, pueden ser computacionalmente costosos de probar. Por ejemplo, el modelo VGG16 (Simonyan y Zisserman, 2015), que se utiliza para la clasificación de imágenes, tiene aproximadamente 138 millones de parámetros de ajuste. La preparación de modelos de este tamaño requiere una capacidad informática grande y costosa, que no siempre resulta accesible.
Una vez que se desarrolla el modelo de IA, es importante que los resultados sean humanamente comprensibles y aceptables. Esto puede resultar problemático de conseguir porque no existe una interfaz general hombre-máquina lista para usar que proporcione información sobre cómo y por qué el modelo de IA toma ciertas decisiones. Por ello, muchos investigadores trabajan para desarrollar soluciones de IA fiables. En la modelización y evaluación de modelos es importante, por ejemplo, tener una formulación precisa del problema y de los requisitos y expectativas de la solución basada en IA. Solo entonces se puede desarrollar un modelo y una estrategia de aprendizaje adecuados para abordar el problema. Además, comprender la configuración precisa también ayuda a elegir y desarrollar los criterios de evaluación correspondientes.
Para un modelo basado en la IA que se considera listo para la implementación operativa, es importante tener en cuenta los retos antes mencionados, relacionados con los datos y el desarrollo de modelos, así como los vinculados a la notificación al usuario. Estos se exploran mediante tecnologías de comunicación basadas en la IA. Para mejorar y facilitar la interpretación de las salidas de los modelos de IA, deben traducirse y visualizarse según las necesidades del usuario final. Por lo tanto, es fundamental que las partes interesadas, desde las comunidades locales hasta los gestores de sistemas de emergencia, y los responsables de las respuestas frente a desastres de las ONG se incluyan en el diseño y la evaluación de sistemas de aviso y alerta temprana, predicciones, mapas de peligros, sistemas de apoyo a la toma de decisiones, paneles de información, asistentes virtuales y otras herramientas de comunicación mejoradas por la IA. La retroalimentación y la evaluación oportunas de los conocimientos del modelo de IA por parte de los responsables de la respuesta a los desastres es esencial para mejorar la calidad y la precisión de la información. La transparencia de las fuentes de datos incorporadas, la frecuencia de actualización de los datos y los algoritmos utilizados para las herramientas de comunicación es esencial para desarrollar la confianza y el perfeccionamiento de las recomendaciones basadas en el aprendizaje automático. Al igual que en la modelización tradicional, transmitir los niveles de confianza, las incertidumbres y las limitaciones de un sistema mejorado por la IA de una manera comprensible resulta crucial para la toma de decisiones informadas. En última instancia, la confianza en las herramientas de comunicación puntuales y totalmente transparentes basadas en la IA es el mayor reto que hay que superar, y ello requiere una colaboración eficaz entre responsables experimentados en la respuesta frente a desastres, desarrolladores de IA, geocientíficos, reguladores, organismos gubernamentales, ONG, empresas de telecomunicaciones y otros, para satisfacer las necesidades de todas las partes interesadas. Cada tipo de catástrofe es único, y cada región tiene diferentes vulnerabilidades y niveles de resiliencia.
Esfuerzos para abordar los retos del uso de la IA en la RRD
Se están llevando a cabo esfuerzos concertados para abordar los numerosos retos que sugiere la utilización de la IA en la RRD y para facilitar su uso, y que apoyan una mayor disponibilidad de datos, proporcionan herramientas y paquetes para ayudar al desarrollo de la IA, mejoran el grado de explicación de los modelos, ofrecen nuevas aplicaciones para los métodos basados en la IA (es decir, gemelos digitales) y contribuyen al desarrollo de normas.
Como ya se ha destacado, uno de los mayores retos en el desarrollo de un algoritmo de IA para la RRD es la recopilación de datos con un muestreo correcto y una suficiente representación de cada patrón para un problema dado. En este sentido, las bases de datos abiertas (o “bases de datos de análisis comparativo”)5,6,7 pueden ser un recurso valioso. Al abrir sus datos, los equipos esperan facilitar que otros investigadores utilicen los recopilados para mejorar y aumentar las soluciones existentes. Para lograr este objetivo, los datos suministrados deben estar bien documentados (incluidos los metadatos) y ser accesibles. Deben tomarse medidas para bloquear, eliminar o editar los datos, a fin de evitar la difusión involuntaria de información personal. Asimismo, es aconsejable proporcionar una documentación clara sobre cómo descargar y comenzar a trabajar con los datos. Muchos equipos abren sus proyectos con una documentación excelente, pero no ven un aumento de los casos de uso debido a la falta de visibilidad; algo que puede resolverse si se ofrecen enlaces a los datos abiertos en Google Datasets, Kaggle, Github u otras plataformas de localización de datos. El GEO, la NASA y la Agencia Espacial Europea, entre otros, han creado directrices y/o bases de datos para apoyar la estrategia de datos abiertos.
 Figura 5. Imagen anotada recuperada con la herramienta de búsqueda de cosmovisión SpaceML de la NASA, que muestra el huracán Sam sobre el océano Atlántico el 29 de septiembre de 2021, tal y como lo captó NOAA-20/VIIRS. Las herramientas innovadoras (basadas en la IA) pueden automatizar la identificación de fenómenos atmosféricos y desastres naturales como los huracanes a partir de imágenes de satélite. Figura 5. Imagen anotada recuperada con la herramienta de búsqueda de cosmovisión SpaceML de la NASA, que muestra el huracán Sam sobre el océano Atlántico el 29 de septiembre de 2021, tal y como lo captó NOAA-20/VIIRS. Las herramientas innovadoras (basadas en la IA) pueden automatizar la identificación de fenómenos atmosféricos y desastres naturales como los huracanes a partir de imágenes de satélite. |
Además de los datos de código abierto, los desarrolladores de IA pueden beneficiarse de una serie de herramientas que ayudan en los principales aspectos para su implantación: recopilación de datos, y desarrollo, implantación y reajuste/ seguimiento de modelos. Dentro de cada uno de ellos, existen varias herramientas privadas y de código abierto para los desarrolladores. Por ejemplo, muchos científicos confían en las imágenes de código abierto para que un equipo de investigación las etiquete a mano. Sin embargo, los sistemas de archivos compartidos que ayudan a recopilar datos y a automatizar anotaciones (por ejemplo, las características relevantes en las imágenes de satélite; figura 5) pueden aumentar la eficiencia. Una vez que los datos se han etiquetado, el profesional de aprendizaje automático y ciencia de datos debe utilizar los paquetes más conocidos (por ejemplo, Python Tensorflow, Keras y Pytorch). Hay numerosas configuraciones populares de arquitectura y ajuste de modelos que permiten simplificar los esfuerzos de la IA. Por ejemplo, Pytorch Lightning está construido sobre Pytorch y es un marco que ayuda a gestionar los datos dentro de los modelos individuales. Por último, con respecto a la implantación y el seguimiento de los modelos, existen soluciones que pueden ejecutarse internamente (es decir, sin la nube), lo que requiere un servidor de modelos dedicado con garantías de disponibilidad y latencia. Sin embargo, antes de ejecutar una solución de este tipo, sería prudente considerar los casos de uso, el coste de los recursos, el número de personal capacitado para garantizar la disponibilidad del modelo y, por último, la frecuencia con la que cabe esperar que se necesite reajustar el modelo. Los sistemas como AWS Lambda y Gateway, Sagemaker, la plataforma de IA de Google y la implantación de modelos de Watson gestionan servidores para tareas específicas de aprendizaje automático, pero aún necesitan recursos de dicho aprendizaje y ciencia de datos para garantizar la precisión, el reajuste y la disponibilidad del modelo.
Cuando se ha desarrollado un modelo, la situación de “caja negra” constituye una advertencia para su uso en aplicaciones de alto riesgo. ¿Cómo puede confiarse en el modelo si no se puede descifrar su proceso de toma de decisiones? La IA explicable es un campo de investigación muy activo, que está generando herramientas que pueden utilizarse durante las diferentes etapas del ciclo de vida de la IA. Por ejemplo, los modelos de IA suelen ajustarse con un gran conjunto de datos para obtener precisiones muy elevadas. Sin embargo, las razones por las que un determinado modelo funciona mejor o peor que otro no suelen estar claras. Con el uso de las herramientas de IA explicable como los gradientes integrados (Sundararajan y otros, 2017) o la propagación de relevancia por capas (Bach y otros, 2015), se puede analizar el modelo y la importancia de sus características aprendidas en los datos de entrada para determinar qué es lo más relevante para una predicción. Al pasar de estos métodos locales a los globales de IA explicable, se pueden identificar los desequilibrios de los datos e incluso se pueden desaprender los mecanismos (Anders y otros, 2022).
Las oportunidades revolucionarias de aprovechar la IA para mejorar los enfoques y servicios de RRD están motivando el intercambio de datos de código abierto, el desarrollo de herramientas y la mejora de la investigación relacionada con la IA (como en la IA explicable). Por ejemplo, se espera que los gemelos digitales de la Tierra (es decir, las réplicas digitales del sistema Tierra y sus componentes) den lugar a avances esenciales en la construcción de ecosistemas digitales innovadores (Nativi y otros, 2021) con consorcios de computación de alto rendimiento (HPC) con unidades de procesamiento gráfico (GPU) y central (CPU), orientados a usuarios y servicios, así como infraestructura dedicada de programas informáticos (Bauer y otros, 2021). En este contexto, la Comisión Europea ha puesto en marcha la iniciativa Destino Tierra, en la que algunos de los primeros gemelos y casos de uso identificados están orientados a la RRD. La IA desempeñará un papel fundamental en la aplicación y el uso eficaz de los gemelos digitales, permitiendo, por ejemplo, el acoplamiento y la representación completa del componente humano como parte del sistema Tierra.
Otra actividad importante que puede apoyar la aplicación de la IA en la RRD es la normalización, es decir, la creación de directrices reconocidas internacionalmente. Las principales actividades de normalización en el ámbito de la gestión de desastres actualmente se llevan a cabo por organizaciones de normalización (SDO) internacionales, como la Organización Internacional de Normalización (ISO), la Comisión Electrotécnica Internacional y la UIT. Otros organismos de las Naciones Unidas, como la OMM, el PNUMA, la Oficina de las Naciones Unidas para la Reducción del Riesgo de Desastres (UNDRR) y el Programa Mundial de Alimentos (PMA), también contribuyen a la elaboración de reglamentos técnicos, marcos, prácticas recomendadas y normas de facto en este ámbito.
Si bien estos estándares centrados en la tecnología generalmente tienen como objetivo emplear las soluciones existentes en materia de tecnología de la información y las comunicaciones para mejorar la eficiencia operativa de los sistemas de alerta temprana y mantener los servicios necesarios para la recuperación frente a desastres, la normalización de la IA para la RRD ha permanecido, en gran medida, como un territorio desconocido. Reconociendo esto, en diciembre de 2020, la UIT, junto con la OMM y el PNUMA, crearon el Grupo focal sobre inteligencia artificial aplicada a la gestión de desastres naturales que, en la actualidad, está: a) examinando cómo podría utilizarse la IA para los diferentes tipos de peligros naturales que pueden desencadenar desastres; y b) redactando las mejores prácticas relacionadas con el uso de la IA para apoyar la modelización a través de escalas espacio-temporales y la difusión de una comunicación eficaz durante estos eventos. El citado Grupo cuenta con diez grupos temáticos activos que exploran la aplicación de la IA a crecidas, tsunamis, plagas de insectos, deslizamientos de tierra, aludes, incendios forestales, enfermedades transmitidas por vectores, erupciones volcánicas, tormentas de granizo y vendavales, y riesgos múltiples, y está revisando activamente propuestas sobre temas adicionales. Con el fin de subrayar y comprender las brechas de normalización en esta aplicación, el Grupo focal también está elaborando una hoja de ruta que contiene las normas y directrices técnicas existentes al respecto por parte de diferentes SDO internacionales, nacionales y regionales. Esta hoja de ruta permitirá identificar áreas futuras que requieren atención en el frente de la normalización. Además, el Grupo está preparando un glosario que recoge los términos y definiciones existentes relacionados con el tema para garantizar una comunicación clara e inequívoca y la coherencia dentro de la corriente de normalización de la RRD.
Próximos pasos
En el ámbito de la RRD, hay un gran interés por explorar las ventajas de utilizar la IA para reforzar los métodos y estrategias existentes. Este artículo presentó varios ejemplos específicos que ponen de relieve cómo los modelos basados en la IA están mejorando la RRD; sin embargo, también mostró que la IA conlleva desafíos. Afortunadamente, el compromiso de la IA con la RRD ha motivado la investigación para encontrar soluciones a estos retos y ha inspirado nuevas asociaciones, que reúnen a expertos de múltiples organismos de las Naciones Unidas, de varios campos científicos (informática, geociencias), de diversos sectores (desde el académico hasta las ONG) y de todo el mundo. Estas asociaciones son fundamentales para impulsar la IA en la RRD. En particular, aún se necesitan esfuerzos en la creación de material educativo para apoyar el desarrollo de capacidades, para garantizar la disponibilidad de recursos computacionales y de más equipos informáticos, y para reducir la brecha digital. Solo así se podrá asegurar que nadie se quede atrás a medida que la IA avanza para la RRD.
Para los Miembros de la comunidad de la OMM que están interesados en saber más sobre la aplicación de la IA a la RRD, hay muchos comités, conferencias e informes que pueden utilizarse como recurso. Por ejemplo, el Comité sobre inteligencia artificial aplicada a las ciencias medioambientales de la Sociedad Meteorológica de los Estados Unidos y la IA del cambio climático, ofrecen la oportunidad de relacionarse con otros expertos en este campo. La reunión sobre IA aplicada a las ciencias de la Tierra, celebrada con motivo de la reciente conferencia NeurIPS sobre sistemas de procesamiento de información neuronal, o la reunión sobre Inteligencia artificial aplicada a la gestión de peligros y desastres naturales, a celebrarse con motivo de la próxima Asamblea General de la Unión Europea de Geociencias, son dos ejemplos de conferencias que presentan investigaciones innovadoras y casos de uso. Por último, informes como “Responsible IA for Disaster Risk Management: Working Group Summary” (“Resumen del grupo de trabajo sobre IA responsable de la gestión de riesgos de desastre”) pueden ofrecer otro enfoque adicional.
Prochaines étapes
Dans le domaine de la réduction des risques de catastrophe, l’IA suscite un intérêt considérable en tant que moyen de renforcer les méthodes et stratégies existantes. Cet article a évoqué plusieurs cas d’utilisation montrant comment les modèles fondés sur l’IA peuvent améliorer la prévention des catastrophes. Cependant, il a aussi montré que l’IA ne va pas sans poser de problèmes. Heureusement, le potentiel prometteur de l’application de l’IA à la réduction des risques de catastrophe incite les chercheurs à trouver des solutions à ces défis et a donné lieu à de nouveaux partenariats, qui réunissent des experts spécialisés dans différents domaines scientifiques (informatique, géosciences), issus de divers organismes du système des Nations Unies, de divers secteurs (des universités aux ONG) et de toutes les régions du monde. De tels partenariats sont essentiels pour faire progresser l’utilisation de l’IA dans la réduction des risques de catastrophe. Nous pensons en particulier que des efforts supplémentaires seront nécessaires pour créer des outils didactiques permettant de renforcer les capacités, pour assurer une offre suffisante de ressources informatiques et d’autres matériels et pour réduire la fracture numérique. Ce n’est qu’ainsi que nous pourrons nous assurer que les progrès accomplis dans l’application de l’IA à la prévention des catastrophes ne laissent personne de côté.
Les membres de la communauté météorologique mondiale qui souhaitent en savoir plus sur cette application de l’IA peuvent se tourner vers les nombreux comités, conférences et rapports consacrés à cette question. Par exemple, le Comité des applications de l’intelligence artificielle aux sciences de l’environnement de l’American Meteorological Society et Climate Change AI offrent la possibilité de nouer des contacts avec d’autres experts du domaine. La séance consacrée à l’«intelligence artificielle pour les sciences de la Terre» lors de la récente conférence sur les systèmes de traitement de l’information neuronale (NeurIPS) et celle qui traitera de l’«intelligence artificielle pour la gestion des dangers et catastrophes naturels» lors de la prochaine Assemblée générale de l’Union européenne des géosciences sont deux exemples de conférences qui font découvrir des recherches et des cas d’utilisation très novateurs. Enfin, des rapports tels que «Responsible AI for Disaster Risk Management: Working Group Summary» peuvent donner des orientations supplémentaires.
Notes de bas de page
Autores
por Monique Kuglitsch, Instituto Fraunhofer Heinrich Hertz (Alemania); Arif Albayrak, Centro Goddard de Vuelos Espaciales de la Administración Nacional de Aeronáutica y el Espacio (NASA) de los Estados Unidos de América (EE.UU.); Raúl Aquino, Universidad de Colima (México); Allison Craddock, Laboratorio de investigación sobre la propulsión de la NASA e Instituto de Tecnología de California (EE.UU.); Jaselle Edward-Gill, Instituto Fraunhofer Heinrich Hertz (Alemania); Rinku Kanwar, IBM (EE.UU.); Anirudh Koul, Pinterest (EE.UU.); Jackie Ma, Instituto Fraunhofer Heinrich Hertz (Alemania); Alejandro Marti, Mitiga Solutions y Barcelona Supercomputing Center-Centro Nacional de Supercomputación (España); Mythili Menon, Unión Internacional de Telecomunicaciones; Ivanka Pelivan, Instituto Fraunhofer Heinrich Hertz (Alemania); Andrea Toreti, Centro Común de Investigación de la Comisión Europea (Italia); Rudy Venguswamy, Pinterest (EE.UU.); Tom Ward, IBM (EE.UU.); Elena Xoplaki, Universidad de Giessen (Alemania); y Anthony Rea y Jürg Luterbacher, Secretaría de la OMM
Références
Anders, C. J., L. Weber, D. Neumann, W. Samek, K.-R. Müller, S. Lapuschkin, 2022: Finding and removing Clever Hans: Using explanation methods to debug and improve deep models. Information Fusion, 77, 261-295.
Astafyeva, E., 2019: Ionospheric detection of natural hazards. Reviews of Geophysics, 57, 1265-1288. doi: 10.1029/2019RG000668
Bach, S., A. Binder, G. Montavon, F. Klauschen, K.-R. Muller, and W. Samek, 2015: On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation. PLoS ONE, 10(7):e0130140.
Bauer, P., P.D. Dueben, T. Hoefler, T. Quintino, T.C. Schulthess, and N.P. Wedi, 2021: The digital evolution of Earth-system science. Nature Computational Science 1, 104-113.
Brissaud, Q., and E. Astafyeva, 2021: Near-real-time detection of co-seismic ionospheric disturbances using machine learning, Geophysical Journal International, in review.
Carrano, C., and K. Groves, 2009: Ionospheric Data Processing and Analysis. Workshop on Satellite Navigation Science and Technology for Africa. The Abdus Salam ICTP, Trieste, Italy.
Ibarreche, J., R. Aquino, R.M. Edwards, V. Rangel, I. Pérez, M. Martínez, E. Castellanos, E. Álvarez, S. Jimenez, R. Rentería, A. Edwards, and O. Álvarez, 2020: Flash Flood Early Warning System in Colima, Mexico. Sensor Journal 20(18), 5231. doi: https:// doi.org/10.3390/s20185231
Iglewicz, B., and D. C. Hoaglin, 1993: Volume 16: How to Detect and Handle Outliers. The ASQC Basic References in Quality Control: Statistical Techniques.
Lu, Y., L. Luo, D. Huang, Y. Wang, and L. Chen, 2020: Knowledge Transfer in Vision Recognition. ACM Computing Surveys 53(2), 1-35. https://doi. org/10.1145/3379344
Martire, L., V. Constantinou, S. Krishnamoorthy, P. Vergados, A. Komjathy, X. Meng, Y. Bar-Sever, A. Craddock, and B. Wilson, 2021: Near Real-Time Tsunami Early Warning System Using GNSS Ionospheric Measurements. American Geophysical Union, New Orleans, Louisiana, USA.
Mendoza-Cano, O., R. Aquino-Santos, J. López-de la Cruz, R. M. Edwards, A. Khouakhi, I. Pattison, V. Rangel-Licea, E. Castellanos-Berjan, M. A. Martinez- Preciado, P. Rincón-Avalos, P. Lepper, A. Gutiérrez- Gómez, J. M. Uribe-Ramos, J. Ibarreche, and I. Perez, 2021: Experiments of an IoT-based wireless sensor network for flood monitoring in Colima, Mexico. Journal of Hydroinformatics 23(3), 385-401. doi: https://doi.org/10.2166/hydro.2021.126
Meng, X., A. Komjathy, O. P. Verkhoglyadova, Y.-M. Yang, Y. Deng, and A. J. Mannucci, 2015: A new physics-based modeling approach for tsunami-ionosphere coupling. Geophysical Research Letters 42, 4736–4744. doi:10.1002/2015GL064610
Moreno, C., R. Aquino, J. Ibarreche, I. Pérez, E. Castellanos, E. Álvarez, R. Rentería, L. Anguiano, A. Edwards, and P. Lepper, 2019: Rivercore: IoT device for river water level monitoring over cellular communications. Sensor Journal 19(1), 127. doi: https://doi.org/10.3390/s19010127
Nativi, S., P. Mazzetti, and M. Craglia, 2021: Digital ecosystems for developing digital twins of the Earth: the Destination Earth case. Remote Sensing 13, 2119.
Nikos, K., M. Avgeris, D. Dechouniotis, K. Papadakis-Vlachopapadopoulos, I. Roussaki, and S. Papavassiliou, 2018: Edge Computing in IoT Ecosystems for UAV-Enabled Early Fire Detection. IEEE International Conference on Smart Computing (SMARTCOMP) 106-114. doi: 10.1109/ SMARTCOMP.2018.00080
Simonyan, K. and A. Zisserman, 2015: Very Deep Convolutional Networks for Large-Scale Image Recognition. ICLR.
Skamarock, W.C., J.B. Klemp, J. Dudhia, D.O. Gill, L. Zhiquan, J. Berner, W. Wang, J.G. Powers, M.G. Duda, D.M. Barker, and X. Y. Huang, 2019: A Description of the Advanced Research WRF Model Version 4. NCAR Technical NoteNCAR/TN-475+STR. doi: http://library.ucar.edu/research/publish-technote.
Sun, W., P. Bocchini, and B.D. Davison, 2020: Applications of artificial intelligence for disaster management. Natural Hazards 103, 2631–2689. doi: https://doi.org/10.1007/s11069-020-04124-3
Sundararajan, M., A. Taly, and Q. Yan, 2017: Axiomatic attribution for deep networks. Proceedings of the 34th International Conference on Machine Learning, 3319–3328.
Troung, N., K. Sun, S. Wang, F. Guitton, and Y. Guo, 2021: Privacy preservation in federated learning: An insightful survey from the GDPR perspective. Computer & Security 110, 10/2021. doi: https://doi. org/10.1016/j.cose.2021.102402.